The Challenge
So you’re using Apache Spark - Yay!
You’ve been through the fun parts of getting to know Spark’s fluent and rich API, perhaps using Scala; You’ve seen how fast you can go from "nothing" to a "working job" with Spark’s standalone mode; You’ve then witnessed the natural integration with Hadoop-stack technologies like YARN and HDFS, and deployed your job onto a real live cluster! You even managed to stay humble enough to employ your Continuous Integration and Deployment tools, and created a reliable, automatic testing pipeline for your code, congrats!
Done?
As always, the answer is No. The almighty Pareto principle is right again - you got 80% of the work done, but somehow 80% of the effort is still ahead of you. Because “working”, “working well” and “stays working” are not the same, and you’ve learnt that before.
So what’s missing? Feedback.
So what’s missing? Feedback.
- Like every framework, Apache Spark only works so-well if you treat it as a blackbox; To get optimal performance, you'll need to tweak it quite a lot, and for that - you'll need to know what works well and what doesn't
- Apache Spark is a data processing framework, and data has that annoying tendency to change, evolve, or just grow. You need to know about these when they happen
- Although Spark is impressively fault-tolerant, that’s far from saying there are no faults you'll have to handle yourself. If your code always throws IllegalArgumentException for a specific input, no retry would save you
- Distributed systems involve a higher level of complexity, rendering most ad-hoc troubleshooting techniques unusable or harder (“tail log file? Where?”), so you'll need to know where and how to look when something goes south
- If you’re not yet using the DataFrames API, but rather building detailed RDD transformations yourself using the Core API - you'll easily create a sub-optimal flow, resulting in slowness, and you’ll need to know when that happens
Let’s do it then!
Monitoring is a broad term, and there’s an abundance of tools and techniques applicable for monitoring Spark applications: open-source and commercial, built-in or external to Spark. I’ll describe the tools we found useful here at Kenshoo, and what they were useful for, so that you can pick-and-choose what can solve your own needs. Most likely, it will take more than one tool or technique to get all the feedback you require.
Spark’s built-in UI
Spark UI (accessible on driver app's port 4040, by default, or via Spark's History Server) is the first place you'd want to check: you'd go there to verify system is up, to see what’s being executed now, and to get a feeling of what’s fast and what’s slow. In the Jobs view, you can easily identify failed or slow jobs (if the terms job, stage and task are not familiar to you - checkout this excellent talk by Aaron Davidson); drilling down into a specific job shows you the Stages executed for this job, and a nice “DAG Visualization” of the pipeline comprised of these stages, e.g.:
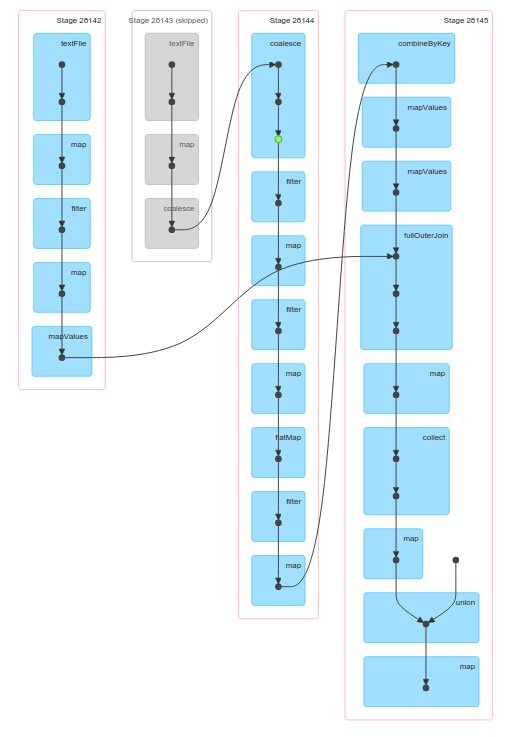
This visualization is specifically useful for identifying RDDs that would benefit from being cached - any “fork” in the graph is a good candidate for caching - as more than one stage will have to calculate the result up to that forking point.
If you drill down further into to a specific Stage, you’ll see its Tasks, the smallest autonomous units of processing in Spark. The detailed data per task can help identify your current bottleneck (large shuffles, GC time, “straggler” tasks taking much longer than others etc.). For example, in this zoomed-out Event Timeline (showing all tasks placed on a timeline and grouped by executor), can you spot the one node being much slower than the others?
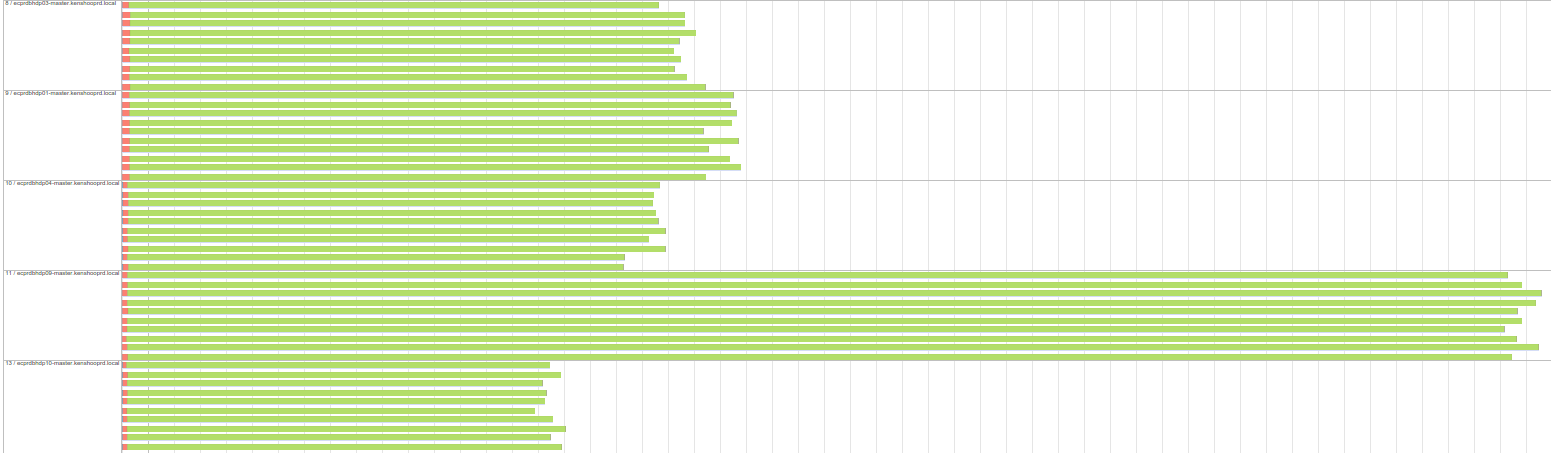
The Tasks page also aggregates this information by executor, making it easy to isolate issues with specific nodes. There's also a useful Executors page showing some high-level stats for currently-running executors. Altogether, the Spark UI is definitely the place to start with for any new Spark code: the big issues will make themselves visible immediately.
Spark’s REST API
Though nice and intuitive, the UI is only useful for looking at one item at a time, but is lacking when you want to derive insights from many jobs or stages at once. That’s when you can use Spark’s REST API - it gives you programmatic access to exactly the same data you see in the UI, but now - you can manipulate it as you’d like.
For example, at one point we’ve asked ourselves “how much of the shuffle data gets spilled to disk, if at all”, during a day-long execution of various jobs, in an attempt to make some informed decisions for setting “spark.shuffle.memoryFraction”. Looking for this information in the UI is futile when you have many jobs, each potentially behaving differently. So, we wrote this little piece of Scala code, to fetch, parse and sum the data for all stages:
The printed result:
stages count: 1435
shuffleWriteBytes: 8488622429
memoryBytesSpilled: 120107947855
diskBytesSpilled: 1505616236
And now we know ~120GB spilled to disk - perhaps we can increase the memoryFraction for shuffle to speed things up! Or maybe we should now improve this code to see what types of stages spill to disk, and handle them specifically?
Other questions of this nature were solved just as easily using other REST API end-points (jobs, storage).
Other questions of this nature were solved just as easily using other REST API end-points (jobs, storage).
Setting up Spark’s Sinks
So these were all manual methods to analyze Spark’s performance post-hoc. What about getting some near-real time information you can act upon? The good folks writing Spark thought about that too, and they collect some interesting internal metrics using the Metrics java library (which we use extensively in Kenshoo as well). These metrics are collected into some in-memory registry on every Spark component (driver application, master, and every executor), but where does it go from there? That’s up to you: you can use Spark’s configuration to set up different sinks for these metrics to "spill" into. In our case, we chose to set up a Graphite sink, since Graphite is where we send all our application metrics (use metrics.properties.template to create the required metrics.properties file). What did we get from this? Well, for example, we can monitor the heap usage on each of our worker nodes:
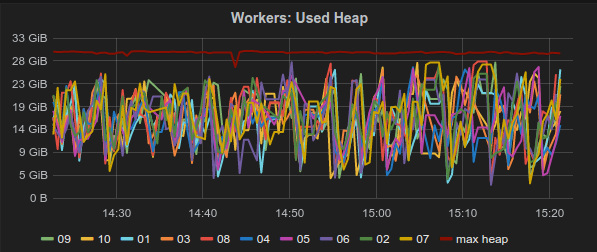
Other useful metrics include number of current jobs and applications, and various JVM information for every component.
Accumulator-based counters
So far we’ve mostly covered Spark’s internals. Another dire need is getting similar data specific to your application. Your data has characteristics you should know about - for example - if you get batches of different sizes, you’d want to know the distribution of these sizes (e.g. mean, max, min..) to optimize your code accordingly.
This specific example often requires counting records in your RDDs. In some cases - this is easy: if your RDD is cached, another count() operation won’t cost much, and is easy to code and send as a metric to graphite. But what if you don’t want to cache this RDD, and you know you’re going to scan it exactly once - is there an efficient way to count records without another scan? This is exactly why Spark authors implemented Accumulators, and in Kenshoo we’ve combined these accumulators with Metrics’ Counters, to have a live metric displaying number of records that passed through a certain pipeline. Here’s a rough example:
The result - more graphs in Graphite!
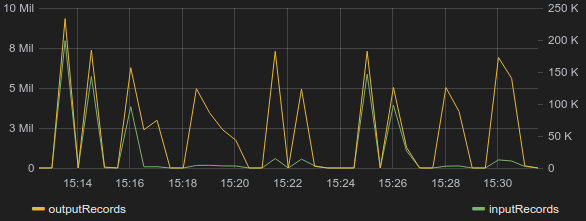
This reusable piece of code makes it rather easy to know how many records pass through any calculation. We've also reduced the annoyance of carrying the "callback" methods through the code by registering them to some "listener" that calls all of them at the end of the entire flow (note that if you call them before any action triggers the RDD evaluation, accumulators will stay zero).
Cache Usage
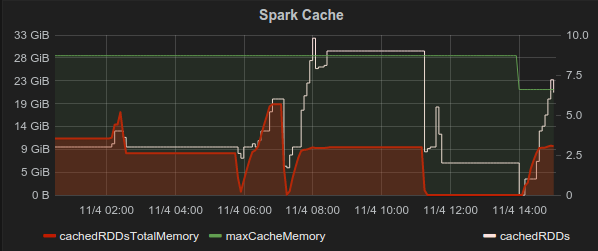
Back to some Spark internals, we recently wanted to know how much of the available cache memory is actually used (to see if we are over/under allocating spark.storage.memoryFraction). Spark doesn’t expose this information in the form of metrics (though it could), but as this post suggests - SparkContext offers access to this information, so all that’s left for us to do is to wrap it with a few Metrics Gauges, to be presented in Graphite like everything else:
And once again, this gives you a useful graphic representation of your system's behavior:
And the list goes on...
Improving our monitoring is a constant theme that accompanies every feature and every new Spark application. These were just a few examples we found interesting or especially useful, but there's plenty more tools and metrics we're using to know how well our apps behave. The bottom line is neither surprising, nor new: the process of building good monitoring must be well structured:
- Ask clear questions first (e.g. "how much cache memory is used")
- Check your existing tools (e.g. Spark UI, Metrics+Graphite) to see if they can answer them
- If not - check for other existing tools that can


